Python(Spark)でのMIDACOの並列化
| MIDACO 6.0 Python Spark ゲートウェイ | |||
| ・ midaco.py ▼ ・ | |||
| 上記ゲートウェイは複数のソリューション候補を並行して実行するため、 マルチプロセッシングの代わりにSparkを使用します。 |
Apache SparkによるMIDACOの並列化は
Amazon EC2、Google Cloud、IBM Cloud、Digital Ocean等の
クラウドコンピューティングシステムや多くの学術機関が提供する
個別の仮想マシン(VM)からなるクラスタシステムでの(大規模な)並列化で特に有用です。
| Sparkクラスタのセットアップ(Linux) | |
| ステップ 0.1 | 複数の仮想マシン(VM)をセットアップします。それぞれのVMには独自のIPアドレスがあります。 例)- IP-VM1 = 100.100.10.01、- IP-VM2 = 100.100.10.02、- IP-VM3 = 100.100.10.03。 各VMがSSHキーを使って相互にアクセスできるようにします。 |
| ステップ 0.2 | Sparkをダウンロードします。https://spark.apache.org/downloads.html 例)spark-2.3.0-bin-hadoop2.7.tgz (Apache Hadoop用に事前構築されたもの) |
| ステップ 0.3 | 解凍したSparkフォルダのコピーを各VMに保存します。 名前はたとえば「spark」とします。 |
| ステップ 0.4 | 1台のVM(たとえば100.100.10.01)をマスターノードとして選択し、以下のコマンドを実行します。 |
| ステップ 0.5 | 他の各VMをスレーブノードとして選択し、以下のコマンドを実行します。 |
| ステップ 0.6 | これで Spark クラスタが起動し、実行されます。 ブラウザでアドレス 「 |
| クラスタ上でのMIDACOの実行 | |
| ステップ 1 | MIDACO python sparkゲートウェイ▼をダウンロードします。 |
| ステップ 2 | 適切なライブラリファイル midacopy.dll または midacopy.so をこちらからダウンロード▷します。 |
| ステップ 3 | サンプル(たとえば「example.py ▶」)をダウンロードします。 |
| ステップ 4 | 以下のようなコマンドによりSparkクラスタ上でMIDACOを実行します。 |
| 注:高度なText-I/Oのサンプル▷は、Sparkでの使用に特に適しています。 | |
32コアのクアッドコアCPUを備えるSparkクラスター上で動作する
MIDACOのスクリーンショット▶
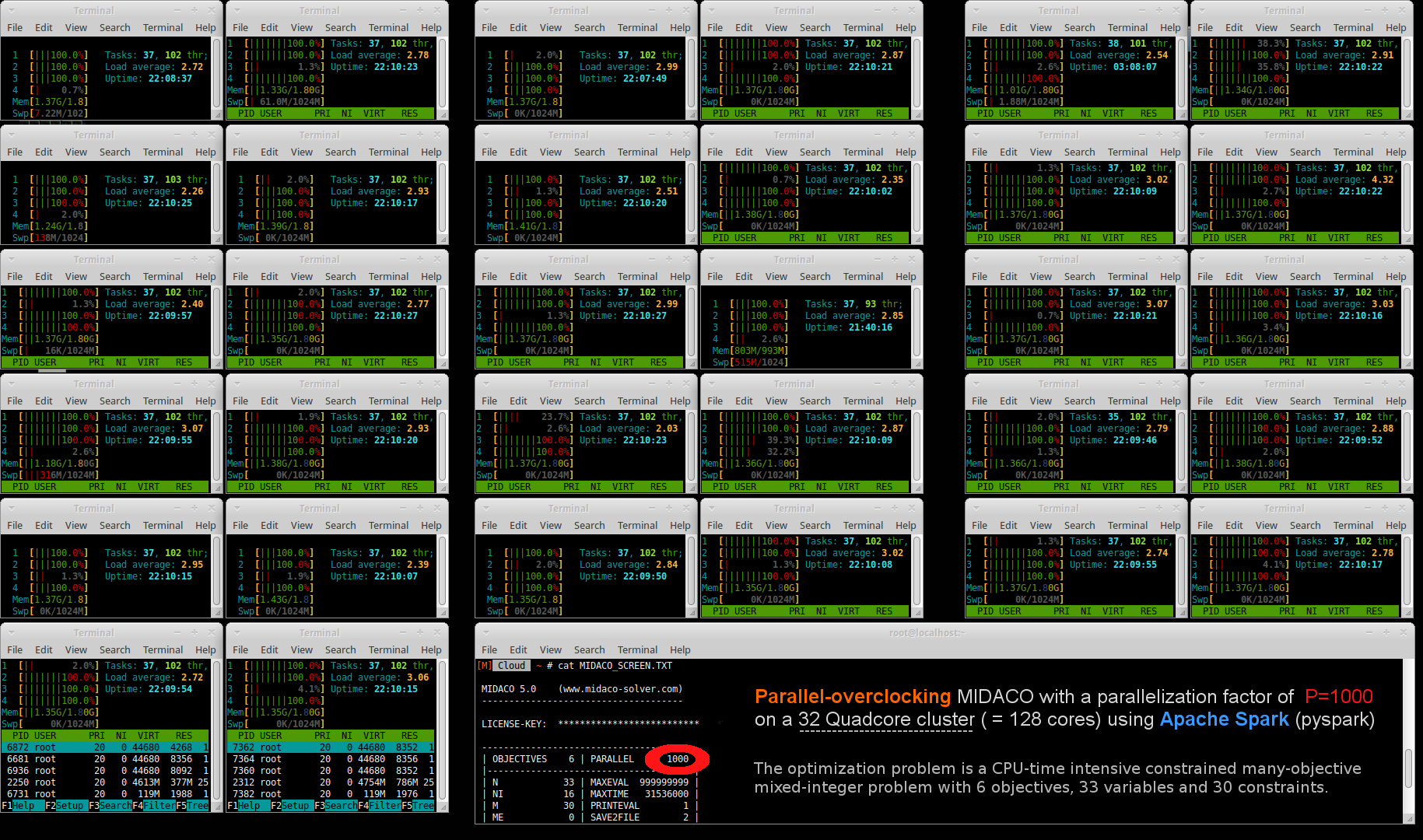
MIDACO−Spark用の詳しい手順ガイドは【作成中】です
以下は36台のマシンからなるSparkクラスタ用の予備的なbashスクリプトです。
注:midaco.py▼自体に含まれるSpark関連コマンドはわずかしかありません。
[Line 24] from pyspark import SparkContext
[Line 237] sc = SparkContext(appName="MIDACO-SPARK-PARALLEL")
[Line 254] rdd = sc.parallelize( A , p ).map(lambda x: problem_function(x))
[Line 256] B = rdd.take(p)